

The Serverless SaaS Playbook
By Guilherme Dalla Rosa
Welcome to AWSCQ.
It’s been a while. We’ve missed you!
But we’re here to make it up to you and we have a few issues lined up that we’ll be releasing in the coming weeks.
First up we’re very happy to say that we’ve got Guilherme Dalla Rosa at the helm.
Other than being a speaker at the upcoming AWS Community Summit in our glorious Manchester this September (more on that at the end of this issue), Guilherme is CTO at MerCloud and an AWS Community Builder in the Serverless category.
Mercloud runs a B2B e-commerce platform with a serverless-first mindset.
Guilherme tell us that approach drives how they serve many customers at once, move fast, and keep uptime and spend in check as they scale.
Be sure to give them a click once you’re done reading!
Over to you Guilherme!

Introduction
Serverless can be a perfect match for SaaS: elastic by design, pay-for-value, and built on managed services. But succeeding with it isn’t about wiring services together, it’s about setting clear guardrails: tenant boundaries that are easy to reason about, data paths that behave under load, and event-driven workflows that fail small. The strongest teams treat platform concerns like auth, isolation, observability, and cost control as product features. With the right patterns, you get tighter feedback loops, simpler ops, and the confidence to scale without amplifying risk.
Tenant Isolation
In SaaS, your isolation model sets your blast radius, costs, and how fast you can ship. The three standard models are silo(one set of resources per tenant), pool (everything shared), and bridge (a mix of both). The right choice depends on factors such as compliance, data residency, customer expectations, and the level of control you require over scaling and cost. This multi‑tenant SaaS architecture patterns overview lays out exactly how those isolation models map to real constraints like cost, scale, and compliance.
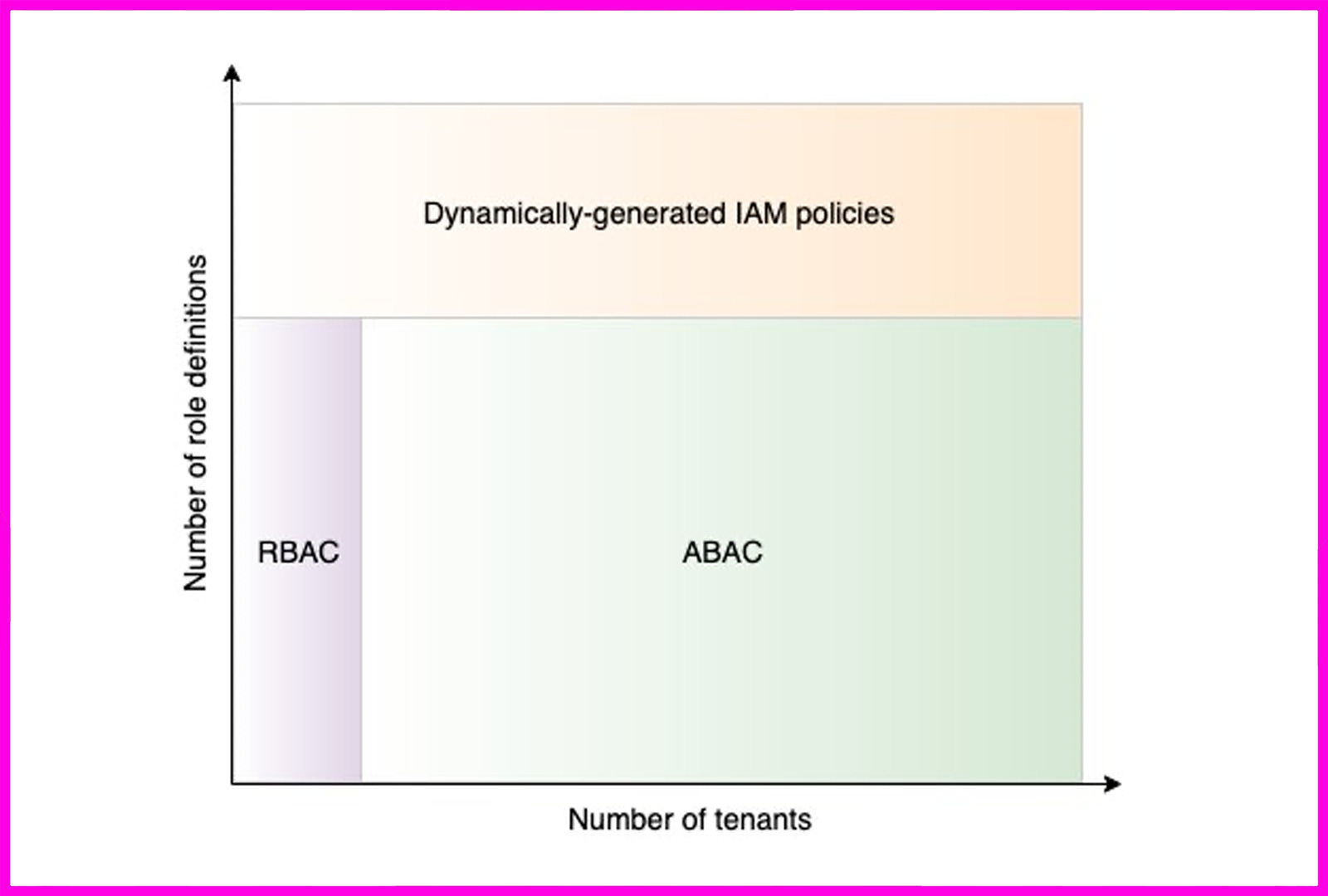
Choosing serverless components that enforce boundaries helps to make isolation by design, and AWS IAM is often a key element in achieving this goal. One of the challenges with using IAM, however, is that the number and complexity of IAM policies you need to support your tenants can grow rapidly and impact the scale and manageability of your isolation model. The ABAC mechanism of IAM provides developers with a way to address this challenge.
DynamoDB fits pooled models nicely when you use tenantId as your partition key and enforce access via an IAM Role and Policy with a condition that ensures tenants can’t see each other’s data, even if something goes wrong. The article **How to isolate tenant data on DynamoDB in a real world use case** walks through this in action, showing how STS session tagging and dynamodb:LeadingKeys enforce reliable, attribute-based isolation. This isn’t foolproof, though: multi-tenant systems often have lopsided data patterns where some tenants generate more traffic and storage than others. That imbalance can create partition hot spots, where a single tenant overloads a shard and slows down your whole table, increasing cost and reducing performance. To mitigate this, you’ll need smarter data distribution.
By the way, this approach isn’t limited to DynamoDB: you can scope S3 by tenant with bucket/prefix patterns or access points, and use Amazon OpenSearch Service fine-grained access control for document-level security. If you’re on relational data with Aurora PostgreSQL, Row Level Security gives per-tenant filters without splitting schemas (and works great with the RDS Data API).
Outbound email just got easier too: Amazon SES now provides tenant-level isolation with automated reputation policies. If one tenant’s campaign spikes bounces or complaints, SES can pause only that tenant while others keep sending—plus you get per-tenant metrics and notifications.
For a deeper dive into tenant isolation, you can watch my session with
Luciano Mammino on Building Secure and Efficient SaaS Platforms on AWS Serverless **where we cover auth, isolation, data partitioning, and guardrails. Slides from the talk are linked in the example repo.

The noisy neighbour
In multi-tenant systems, a “noisy neighbour” is any tenant whose traffic or slow jobs hog shared capacity, pushing up everyone else’s latency and backlogs. It shows up in databases, workers, queues, and even outbound comms. The aim isn’t just speed; it’s fairness and blast-radius control so one tenant’s spike doesn’t become everyone’s incident.
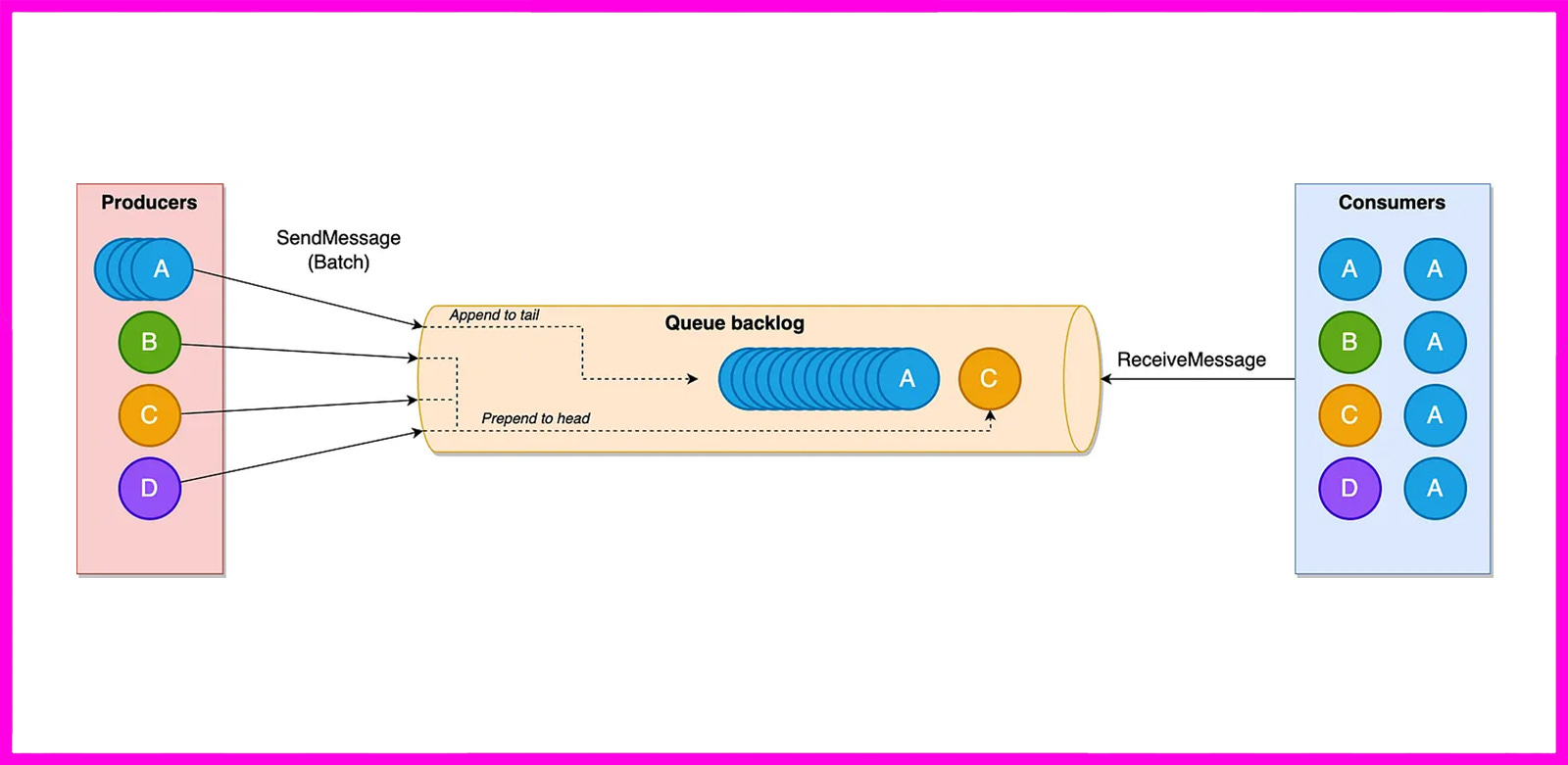
Queues are a classic pressure point. On shared queues, a heavy tenant can head-of-line block others—this is where the new SQS Fair Queues come in. They extend SQS standard queues to mitigate noisy-neighbour impact. By tagging each message with a tenant key via MessageGroupId, SQS will rebalance delivery so quieter groups keep moving; consumers don’t need changes, and new CloudWatch metrics surface fairness and dwell time. Get the gist from the Amazon SQS Fair Queues for fairness in multi-tenant environments **article, then, if you want to see some code, check out the sample repo to test it under load with dashboards and code in place.
In high-traffic setups, teams often put Amazon SQS in front of AWS Lambda to smooth bursts and control concurrency. SQS buffers work while Lambda pulls in batches; you shape throughput with event-source mapping settings (batch size/window, visibility timeout) and put a hard cap in place with Maximum Concurrency on the SQS trigger. Use reserved concurrency to protect downstream systems, and enable partial batch responses (plus a DLQ) so failed items retry without blocking the rest of the batch. If you’d like to level up, the Lambda team’s Handling billions of invocations post and the AWS Bites episode Solving SQS and Lambda concurrency problems are a great combo of real-world lessons and practical tweaks.
DSQL: The new kid in Aurora town
DSQL is a new distributed database that is compatible with Postgres* and promises virtually unlimited scalability. It’s probably one of the easiest databases to set up, and it can deliver five nines of availability in a multi-region cluster setup, getting a 5-star review in the serverlessness scale. The main point of concern is that to enable multi-region, you need to configure a witness region, and currently, DSQL only supports US-based regions for that. This might be a problem if your setup requires data sovereignty.
If you want to have a deep dive into DSQL and take a closer look under the hood to understand how it lives up to its promises, I invite you to the AWS Community Summit that takes place in Manchester on the 25th of September, where I’ll be delivering the talk What DSQL? – Rethinking SQL for the Serverless, Distributed Age. Meanwhile, I recommend checking out the Serverless applications with Java and Aurora DSQL series by Vadym Kazulkin.

DSQL represents a significant shift in how we approach distributed database design, but like any technology, it comes with trade-offs. Let's explore together the specific scenarios when DSQL is the right tool and when another database option will serve you better. But adopting DSQL doesn’t really mean migrating from another solution to it. Lee Gilmorecame up with a great idea to use it as a sidecar to DynamoDB. It looks like an elegant way to get around the challenges of designing a DynamoDB table with multiple and exotic access patterns. It can also be much cheaper than using OpenSearch.
Pricing can be something difficult to predict, as there are many factors to be taken into account. Alessandro Volpeccellahas written a helpful article that hopefully will help clarify some of the mysteries behind it. If you have a spare dollar and want to spend it playing around with DSQL, Mark Bowes’s guide will help you with it.
More news on Serverless Databases
Amazon DocumentDB Serverless is now available: a MongoDB-API–compatible option that auto-scales capacity up and down and charges for what you use. Helpful for spiky or unpredictable workloads, it keeps the familiar DocumentDB features (e.g., read replicas, Performance Insights) without pre-sizing clusters.
DynamoDB also has some interesting news: Global Tables now support multi-Region strong consistency (MRSC), allowing you to choose strong or eventual consistency at table creation. With MRSC, apps can read the latest data from any Region and target zero RPO for resilience-first designs. Donnie Prakoso shares more on this front in the article Build the highest resilience apps with multi-Region strong consistency in Amazon DynamoDB global tables.
Designing your data model that aligns with your application’s access patterns is a key part of unlocking the full potential of DynamoDB. It’s great to see tools like DynamoDB data modelling MCP emerge, especially when they help surface access patterns and model trade-offs early on. Even for experienced developers, it’s a great way to validate and stress-test your table design.
As we’re talking about DynamoDB, I recently came across a clever trick that might surprise you too: Emanuel Russobrought up a use case for DynamoDB TTL + Streams as a timed trigger without cron jobs, polling or schedulers. Sounds like a good solution for cases where we don’t need events to be executed at a precise time, like scheduled notifications or cleanup jobs. It’s elegant, low-overhead, and truly event-driven.
Agentic AI
Enterprise SaaS is embracing AI agents fast, and with it come new requirements: keep solutions efficient, compliant, secure, and scalable—especially as organisations add governance and risk controls around AI programs.
AWS has published prescriptive guidance to help teams do this well in real-world systems that offer strong foundations for designing scalable and safe agentic systems:
Building serverless architectures for agentic AI on AWS, which lays out event-driven agent workflows, cost controls, observability, and resilience;
Building multi-tenant architectures for agentic AI on AWS, which covers tenant-aware memory, resource quotas, isolation, and the separation of control and application planes.
Vector search is becoming the backbone of generative AI. Every time you ask a chatbot a question, there’s a good chance it’s finding the answer by searching through vectors. The hurdle? Managing vectors at scale has been notoriously expensive… until now. Amazon just announced S3 Vectors, a new type of storage offering up to 90% lower cost for vector storage and similarity searches, while retaining S3’s durability and scale. A game-changer when what mattered most was feasibility, not just capability. For a practical overview, check the article Build Cheap and Scalable AI with AWS S3 Vector Storage.
SaaS Factory
If you're looking for essential jumping-off points for building SaaS on AWS, here are some foundational resources worth bookmarking:
AWS SaaS Factory: a central hub of best practices, reference architectures, webinars, and workshops for building SaaS products on AWS.
SaaS on AWS: the official page highlighting why and how SaaS teams leverage AWS for global scale, compliance, rapid launch, and Marketplace reach.
AWS SaaS Factory Bootcamp: a self-guided, hands-on workshop that walks through identity, onboarding, multi-tenant microservices, and data isolation via reference SaaS architecture.
And that’s all from Guilherme.
A huge thanks to him for putting this one together.
As he mentioned you can see Guilherme in his session What DSQL? – Rethinking SQL for the Serverless, Distributed Age at Comsum (AWS Community Summit) on the 25th of Sept.
Guilherme is part of an absolutely stellar line up. Why not go and have a nosey at what we have in store.
If you made it this far then please use the code ‘AWSCQ’ as little reward when you buy your ticket. You’ll get a £15 discount for being so good at reading :)

Finally, before you go be sure to give our sponsors a click!
AWS Community Summit Events and AWSCQ are only possible with their generous support.
There’s often a line drawn between the sponsors and attendees at events but we’re careful who we partner with and these guys are every bit a part a of the community as we are.
Go on - click click click click!
See you for the next one :)







