

Data & Analytics
Let’s talk about data
Welcome back to AWS Comsum Quarterly. This edition’s guest editor is Matt Houghton - Data Architect at CDL Software, AWS Community Builder, AWS Ambassador, 13 x AWS Certified, and Qlik Luminary 50. Matt has been an active member and contributor to the AWS Comsum community since day one. He’s given talks at both our physical and online events, reported from re:Invent in Las Vegas and interviewed Dr Matt Wood at last year’s post-London summit Community Network Evening. We’re delighted to add AWSCQ guest editor to that list.
Over to you Matt….


As organisations across the globe continue to generate and gather vast amounts of data, the ability to harness and make sense of it has become critical to staying ahead of the competition.
AWS provides a range of powerful tools and services that allow businesses to analyse, visualise, and extract insights from their data.
Let’s talk about data
In this edition of the newsletter, we’ll explore some of the latest trends and developments in the world of AWS data and analytics,. We’ll also highlight information from experts in the field who will share their insights and best practices for getting the most out of your AWS data and analytics capabilities.
If you can’t get enough from the links below then AWS Senior Specialist Solution Architect Tony Mullen has started a new series on Twitch.

In the first show Tony and guests talked about GP3 storage with RDS, and Oracle Database Gateway. Tony is happy to take questions from the audience, so if you want to ask a question to his team of architects please tune in.
Optimising Aurora Databases
I first met AWS Community Builder Ganesh Swaminathan in 2021 as we both prepared to talk at the AWS re:Invent conference. Ganesh at the time was speaking on the differences between versions of Amazon Aurora Serverless.

In one of his latest blogs Ganesh has undertaken a mini Well Architected Review following a request to help optimise a database. It’s good to read the process Ganesh went through after being presented with a single screenshot.
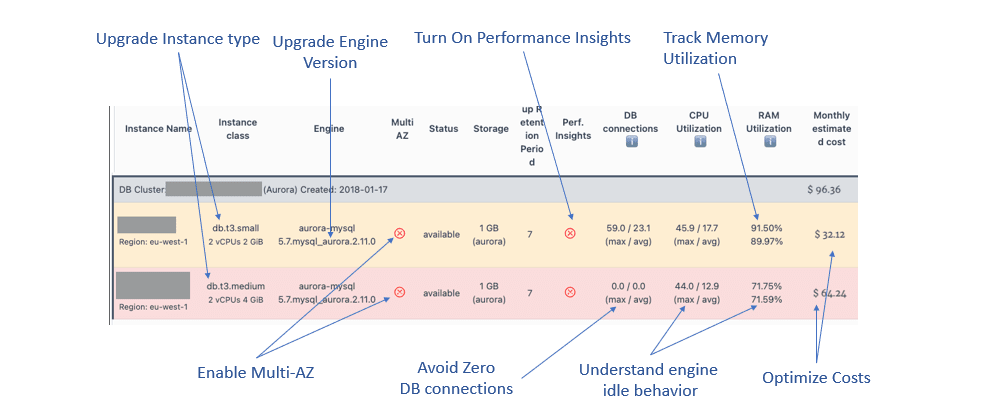
Architecture on a Post-it note: Optimizing AWS Aurora Databases - DEV Community
Do you love OpenSearch?
A new public slack for the open-source OpenSearch project has been launched.
There is promised discussion on current and future development for OpenSearch and the chance to get a better understanding of how it is implemented at a deeper level.
Join here https://opensearch.org/slack.html

In other OpenSearch news the serverless flavour of the AWS managed service has moved to General Availability after launching in preview at AWS re:Invent.
OpenSearch provides very fast search based analytics and visualisations. Data generated by IoT applications is a great use case for the capabilities of OpenSearch.
In this blog AWS Partner Ambassador Shuhei Honma takes us through an introduction to OpenSearch along with cost comparisons. He finishes with an architecture and sample searches for an IoT application

Using Amazon OpenSearch Serverless in AWS IoT Core
Bad data, dirty data
I’ve seen it quoted many times that up to 80% of time on any data and analytics project is spent on getting the data ready to use. This frequently in my experience in part comes down to dealing with legal and compliance requirements of being able to safely and securely share data between partners.
AWS Clean Rooms helps customers and their partners more easily and securely collaborate and analyse their collective datasets—without sharing or copying one another’s underlying data.
In late march the service went into General Availability.

AWS Senior Developer Advocate Donnie Prakoso shares how to get started in his blog.
AWS Clean Rooms Now Generally Available — Collaborate with Your Partners without Sharing Raw Data | AWS News Blog)
Learning Glue
AWS Glue is a serverless data integration service that makes data preparation simpler, faster, and cheaper claim AWS. If you are new to Glue though, even with a managed service, there is a learning curve to getting started quickly. Want to write some ETL using Glue? First you’ll need an S3 bucket to store your data, Glue will need IAM roles and policies to access the data. If you want to catalog the results and make it available to Query using Athena then that’s more S3 buckets for the results and more IAM. This setup can put people off using AWS Glue.
This was just the problem faced by AWS Community Builder Thiago Panini an Analytics Engineer trying his best to deep dive into those services in his personal environment for learning everything he could.
The result of the learning was to help other people new to AWS Analytics services get started quickly. The project Terraglue was created.

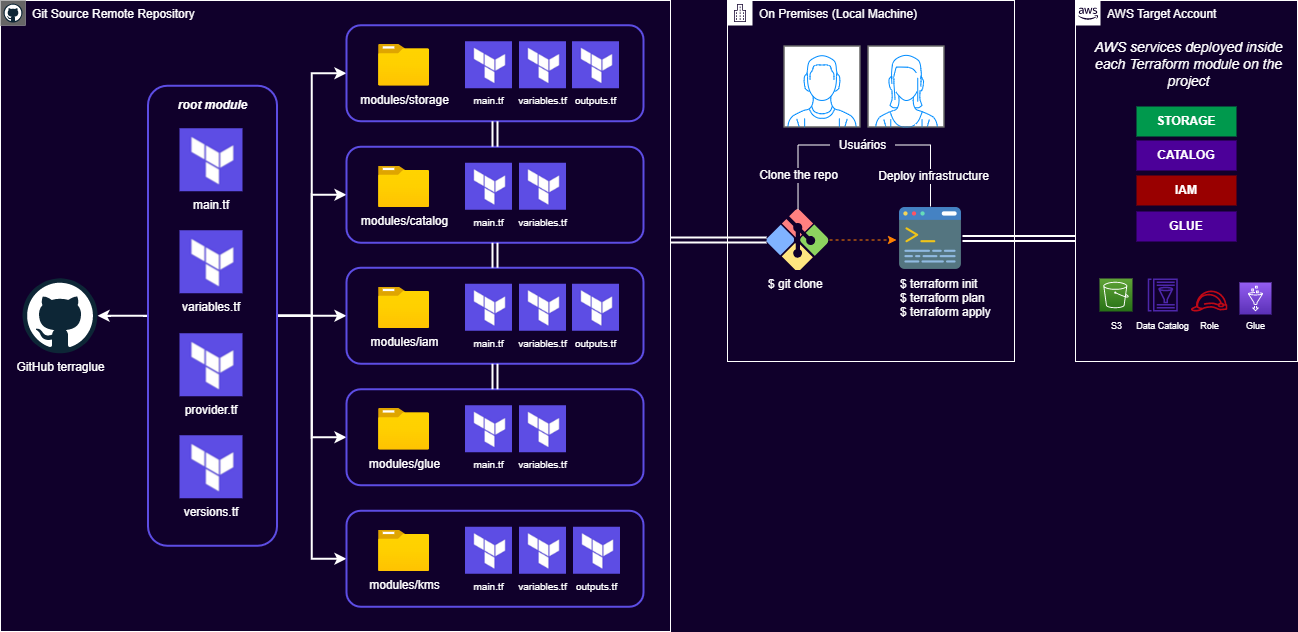
Utilising Terraform, Terraglue defines and creates the following AWS resources allow
S3 buckets for storing data and assets
IAM policies and role for managing access
Databases and tables in the Data Catalog
A Glue job with an end to end ETL example developed using pyspark
The full story on the creation of Terraglue is available on Thiago’s blog
DataZone
Many organisations have data silos, where data is stored in different systems, formats, and locations. This can make it challenging to access, analyse, and share data effectively. Amazon DataZone now in public preview looks to address these issues.
Amazon DataZone includes four main components:
Organisation-wide catalog: Make data visible with business context for everyone to find and understand data quickly. Catalog data across the organisation so you can find and request access to data for analysis.
Publish/subscribe workflow with access management: Use the automated workflow to help secure data between producers and consumers and ensure the right data is accessed by the right users for the right purpose. Streamline auditing of who is using which datasets for what business use case, with the publishing and subscribing workflow.
Data project: Simplify access to AWS analytics by creating business use-case-based groupings of users, data assets, and analytics tools. Amazon DataZone projects provide a collaborative space where project members can collaborate, exchange data, and share artefacts. Projects only allow explicitly-added users to access the data and analytics tools. Individual projects manage the ownership of data assets produced within the project, in accordance with policies applied by data stewards, thus decentralising data ownership through federated governance.
Portal (outside the AWS Management Console): The Amazon DataZone portal is an integrated data experience for users to promote exploration and drive innovation with a personalised homepage. The portal is an out-of-console experience that facilitates cross- functional collaboration while working with data and analytics tools in a self-service fashion. It verifies existing credentials from your identity provider.

Governed Analytics – Amazon DataZone – Amazon Web Services
And that’s a wrap for this edition of AWSCQ. Massive thanks to Matt for being so generous with his time and putting this edition together.
Before we go we’d like to draw your attention to our free Network Evening taking place directly after the AWS Summit in London. 7th June 5pm - Late.
Secure your spot now!
